 t
t

Four years and two days ago, Tim Berners-Lee wrote Reinventing HTML where he infamously admitted:
"It is necessary to evolve HTML incrementally. The attempt to get the world to switch to XML, including quotes around attribute values and slashes in empty tags and namespaces all at once didn't work."
and then went on to announce the plan to charter a completely new HTML group
and a separate group to work on the XHTML2 work which the old "HTML working group" was working on.
with the explicit caveat of independence: There will be no dependency of HTML work on the XHTML2 work.
Similar words were said about XForms. Both moves (accommodating XHTML2 and XForms) were largely political, doomed from the start but perhaps providing a smoother, but slower, more face-saving termination path.
Just over three years after Tim's blog post, W3C announced the end of work on XHTML2:
"...when the XHTML 2 Working Group charter expires as scheduled at the end of 2009, the charter will not be renewed."
Draconian = FAIL
What Tim failed to mention, and what was perhaps the biggest nail in the coffin for use of XML (and thus "real" XHTML) on the web, was its draconian error handling. Here's an actual example I screen-captured:
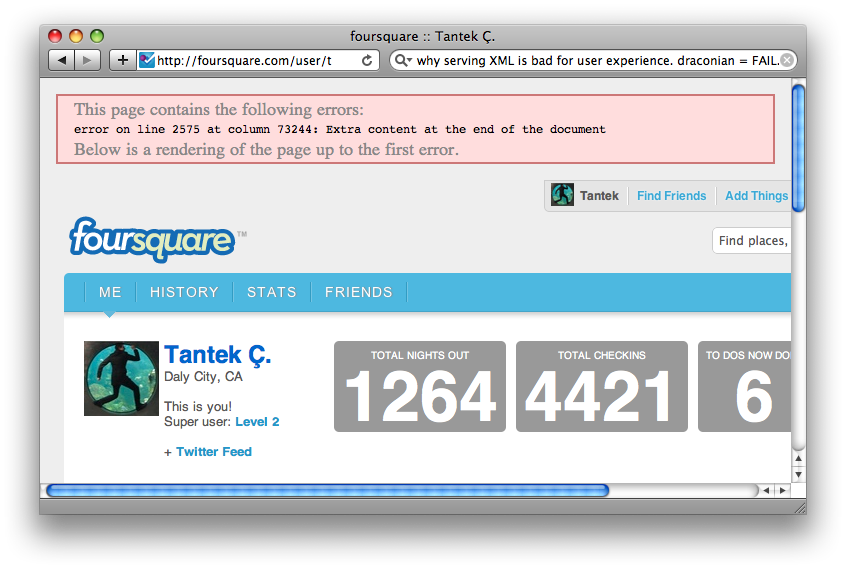
Now, I was actually quite shocked to see this, as in practice nearly nobody (maybe Sam Ruby) serves content as "actual" XML or XHTML (content-type of text/xml, application/xml, or application/xhtml+xml), and this screenshot is exactly why.
It's too easy for content to subtly break some form of XML-validity, and then have the browser provide an ugly and unfriendly warning message like the above. This happens because XML requires that browsers and anybody else that parses XML handle errors in a very draconian manner, that is, to stop processing at the first error.
Given a choice, nearly no one wants the browser to stop displaying because of an error, and thus nearly no one serves XML on the Web.
That's the real reason XML failed. Because a policy of draconian error-handling is a policy of failure.
XHTML coding practices
Getting back to Tim's points, I have no problem with including quotes around attribute values and slashes in empty tags
and in fact have found that doing so, and validating as such, catches more errors sooner for me and thus I (as many web developers do) find it beneficial to code with such XML strictness.
In general the practice of coding "compatible XHTML", based on the informative Appendix C. of the XHTML 1.0 spec, has been fairly well accepted by modern web developers as a best practice.
But there are other aspects of XHTML that have no discernible benefit, for example:
xml:langattributes, in addition tolangattributesxmlns="http://www.w3.org/1999/xhtml"namespace declaration
I haven't bothered with xml:lang attributes in quite some time. However, I have sometimes (inertia?) still included the xmlns XHTML namespace declaration.
Prioritizing, minimizing, and losing some xmlns
When I started coding Falcon (the code that now runs the home page and permalinks of tantek.com), I had to prioritize, minimize, and coded only what I needed.
I used XML-valid HTML5+hAtom as the data store for Falcon. Natively viewable (HTML5), compatible with well known syndication semantics (hAtom), and easily readable/writeable on the server using built-in PHP DOMDocument interfaces.
Eventually I noticed that I had omitted the xmlns XHTML namespace declaration and apparently didn't need it. The client (browser) didn't need it. The server (Falcon/CASSIS/DOMDocument) didn't need it.
The only place I continued to use the xmlns XHTML namespace declaration was in my Atom feed, largely just quickly modeled/copied from my old Atom feed that I used to generate with HyperCard back in the day (only a few years ago, ahem).
Does xmlns stymie Google?
I use the xmlns declaration in a few places in my feed. Everywhere I have content, I wrap it in divs with the xmlns:
<title type="xhtml">of the Atom<feed><title type="xhtml">of each Atom<entry><content type="xhtml">of each Atom<entry>
If you look at my feed in either Safari or Firefox, you'll see the content as you might expect, with some browser-specific feed styling.
If however you view my content through Google Reader, or see it syndicated into Google Buzz, you'll see that every entry shows the feed title with visible <div> markup, having errantly overescaped the contents of the feed's <title> element., e.g.

Nevermind the display of duplicate content from the title and the contents of the entry - Google should know better (either heuristically or due to the use of the Activity Streams note object-type) - but that's a separate bug.
Google has known about the overescaping problem (failure to parse XHTML in Atom <title> elements) for over 3 months now (since July 13th 2010). They eventually added it to their public bug database last month. This seems like a small quick fix that should be trivial for the Google geniuses, and yet, no progress, no comments, and no estimate for when they might look at it.
Google is in many ways helping spearhead and accelerate the development of a Federated Social Web, with their work on PubSubHubbub (including a nice easy to use hub), and work on the Salmon notification specification. These are huge complex tasks. But equally important is rapid iteration and fixing annoying little parsing bugs like incorrect double-escaping of nested XML/XHTML.
To be clear: I'm not asking Google to handle some sort of broken markup for backward compatibility. I'm simply asking Google to parse Atom feeds properly as XML.
Losing my xmlns
I have been fairly outspoken about the failure of namespaces for content, XML namespaces in particular. I use xmlns in Atom only to avoid the even worse practice of escaping markup to embed markup inside markup (what RSS makes you do).
However, remembering four years ago, and my own loss of xmlns in my HTML5 documents, I've decided to drop xmlns from the title of my feed as well - it's not necessary today, and highly doubtful that I'm going to include markup there in the future.
Towards XML-valid HTML5
Longterm I don't believe in Atom, nor any other draconianly fragile XML format. I include Atom simply because for now, it's a part of the glue for the Federated Social Web. In the future I can see replacing it with hAtom, parsed from HTML5 documents.
However, I personally, as a developer and publisher, still see benefits from XML coding practices, not the least of which is being able to maintain HTML5+hAtom data stores (and thus avoid the even worse problem of database maintenance). So for now, I'm going to continue coding my HTML5 with quoted attributes, explicit closing tags, and self-closing empty elements, making them what I call "bi-glot" documents: both HTML5, and valid XML.
I've given up on "proper" XHTML (by any definition). Long Live XML-valid HTML5.








{kind=link}