While researching a way to describe different parts of a URL for a runtime interface, I was shocked to discover that over the years, different specifications, implementations, and communities had developed an incredible variety of ways to slice and name the pieces of a URL.
I remember seeing XKCD 927 recently, laughing at the familiarity, and what appeared at the time to be quite a bit of exaggeration. 14 competing standards, hah.

I was developing a small single purpose microsite and decided to build it using CASSIS not just for application logic, but for the server-side runtime execution and flow as well. I figured the needs of a simple real world site would work well to drive the design of a simple runtime.
No need to invent anything new, just re-use Apache/CGI environment variables (e.g. as used in PHP, like SERVER_NAME). But they look like old C constants, and CASSIS coders will be more familiar with Javascript.
Window.location's properties seem reasonable, until you get to "search" for the "?" query part of a URL. What about the source, the specs for URL and HTTP? And that's when I started to see the problem.
With a little more research I found a half-dozen different ways to slice and dice URLs. Kevin Marks asked me, what about Python? And that made seven. I published my research publicly on the microformats wiki, which is a good place to document existing formats for something (a key step in the microformats process).
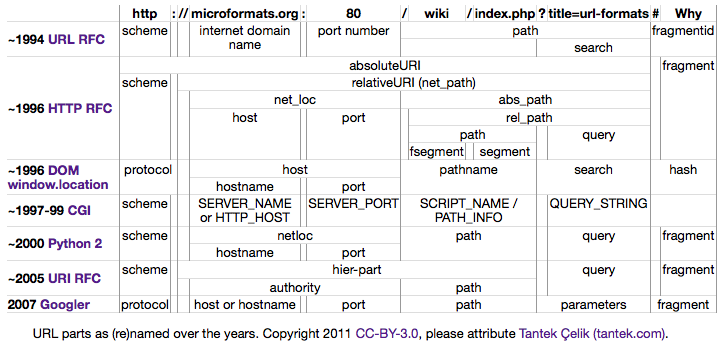
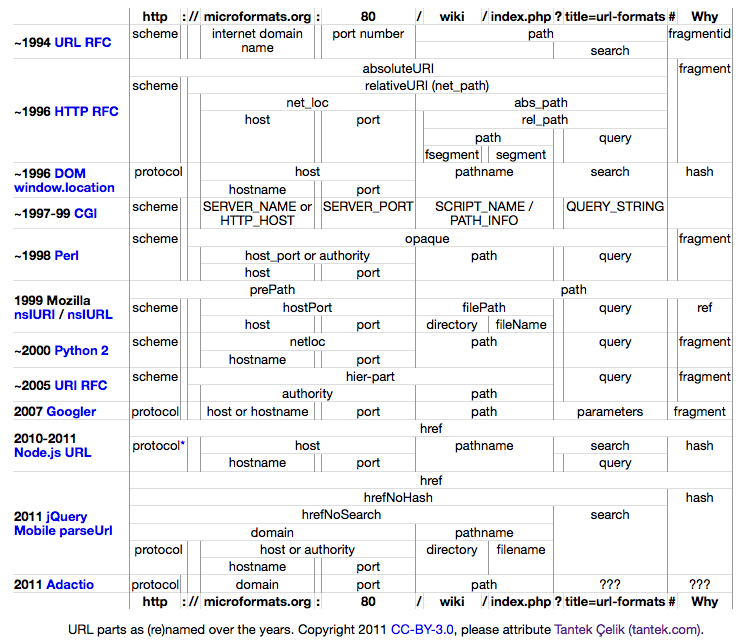
Among all the differences (and overloading of the same terms to mean different things) it did seem that there were some patterns. So I made a diagram of a sample URL, chopped into pieces and named according to seven eight nine ten twelve different conventions over the years, in the hopes that doing so might reveal such patterns.
| http | : | // | microformats.org | : | 80 | / | wiki | / | index.php | ? | title=url-formats | # | Why | |
| ~1994 URL RFC | scheme | internet domain name | port number | path | fragmentid | |||||||||
| search | ||||||||||||||
| ~1996 HTTP RFC | absoluteURI | fragment | ||||||||||||
| scheme | relativeURI (net_path) | |||||||||||||
| net_loc | abs_path | |||||||||||||
| host | port | rel_path | ||||||||||||
| path | query | |||||||||||||
| fsegment | segment | |||||||||||||
| ~1996 DOM window.location | protocol | host | pathname | search | hash | |||||||||
| hostname | port | |||||||||||||
| ~1997-99 CGI | scheme | SERVER_NAME or HTTP_HOST | SERVER_PORT | SCRIPT_NAME / PATH_INFO | QUERY_STRING | |||||||||
| ~1998 Perl | scheme | opaque | fragment | |||||||||||
| host_port or authority | path | query | ||||||||||||
| host | port | |||||||||||||
| 1999 Mozilla nsIURI / nsIURL | prePath | path | ||||||||||||
| scheme | hostPort | filePath | query | ref | ||||||||||
| host | port | directory | fileName | |||||||||||
| ~2000 Python 2 | scheme | netloc | path | query | fragment | |||||||||
| hostname | port | |||||||||||||
| ~2005 URI RFC | scheme | hier-part | query | fragment | ||||||||||
| authority | path | |||||||||||||
| 2007 Googler | protocol | host or hostname | port | path | parameters | fragment | ||||||||
| 2010-2011 Node.js URL | href | |||||||||||||
| protocol* | host | pathname | search | hash | ||||||||||
| hostname | port | query | ||||||||||||
| 2011 jQuery Mobile parseUrl | href | |||||||||||||
| hrefNoHash | hash | |||||||||||||
| hrefNoSearch | search | |||||||||||||
| domain | pathname | |||||||||||||
| protocol | host or authority | directory | filename | |||||||||||
| hostname | port | |||||||||||||
| 2011 Adactio | protocol | domain | port | path | ??? | ??? | ||||||||
| http | : | // | microformats.org | : | 80 | / | wiki | / | index.php | ? | title=url-formats | # | Why | |
URL parts as (re)named over the years. Copyright 2011 CC-BY-3.0, please attribute Tantek Çelik (tantek.com).
I hope you find this diagram useful to both understand the many names for different parts of URLs, and what someone might mean when they use one of them.
Also available in image form (as of 2011-08-26, 720x350)
image form (as of 2011-09-18, 748x644)
{kind=link}
If you publish it, please link it to this blog post: http://tantek.com/b/4DY1
And if you know of other standards, implementations, or even cultural conventions that split up URLs and name the pieces differently than the above, please let me know. Note: username & password were omitted for simplification (and you shouldn't be using http-auth anyway); params omitted because it's obsolete.
A few conclusions:
- scheme is more prevalent than protocol. Yet anecdotally developers use protocol more, and in practice most schemes are protocols.
- hostname is used consistently (to mean the same thing) as are port and query.
- path has been used consistently for the past 10+ years and in a way consistent with its operating system roots.
- fragment(id) is used inconsistently as to whether or not it includes the leading "#" hash/pound symbol. However, notably absent from any specification or platform was the alternative phrase named anchor.
The highlighted subset of terms should work just fine for a new CASSIS web app runtime convention, thus inevitably fulfilling the expectations as documented and foretold by XKCD 927.
Thanks to Erin Jo Richey, Ian Fung, Kevin Marks, Ben Metcalfe, and Violet Blue for feedback and reviewing drafts of the diagram.
Update 2011-08-31: Thanks also to Jeremy Leader for IMing me the info about Perl, including a sample Perl script that slices up the example URL, as well as its output, and 1998 reference to URI library 0.01 readme.
Update 2011-09-01: Thanks to Wladimir Palant for reminding me about the Mozilla XPCOM interfaces nsIURI and nsIURL and their respective IDL files, used by Firefox extension developers.
Update 2011-09-02: I've added Node.js's URL class, originally documented in 2010 because of the debate on github, as well as jQuery Mobile's path.parseUrl thanks to Scott Jehl sending me the results of parsing the example URL into the various properties.
Comments
- 2011-08-26 Hacker News commentary thread
- 2011-09-08 Saveen: A Great Diagram: URL Slicing by Tantek Çelik
- Thanks for the kind words Saveen! t