-
European friends!
🗓 I am going to Beyond Tellerand (@btconf@mastodon.social) Berlin next week 7-8 November and you should too!
BTconf is the best independent web design, development, and inspiration conference in Europe.
Everything from the speakers to the talks to the side events are a labor of love by @MarcThiele.com (@marcthiele@mastodon.social) and his crew, and it shows in the #btconf community he has gathered over the years.
If you’re in #Berlin, or can hop on a train and join us, you should.
🎟 Grab a ticket: https://btco.nf/t
And while you’re there, consider joining us at #IndieWebCamp Berlin right afterwards on 9-10 November (complimentary camp tickets at the same link), for #barcamp style discussions sessions and an #indieweb Create Day, writing, styling, designing, coding, hacking on our personal sites for a better web for ourselves and everyone else.
-
Bing use-case! AKA One Weird Trick Time And Date Sites Hate
In my prior post^1 I noted that I use 'b' as a Search Shortcut for #Bing. Here is why:
* quickly view a Gregorian calendar month display, with readable days, days of the week, and weekends & holidays highlighted.
E.g. I type this into my Firefox address bar:
b dec 2024
then press return and immediately see:
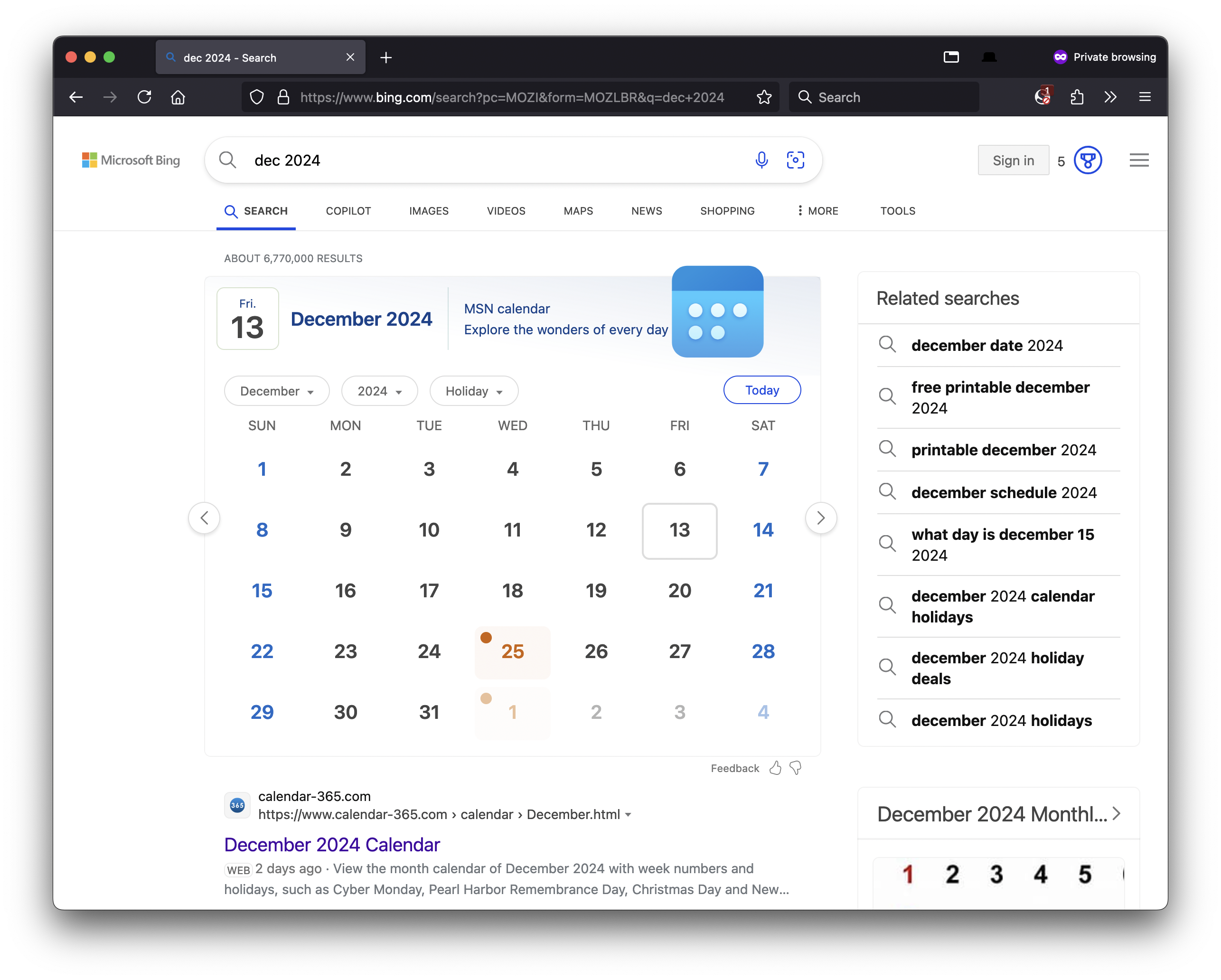
Only Microsoft Bing search supports this.
On other search engines (Duckduckgo, Google, Yahoo) all you get are links to random date time sites littered with ads, or blurry images of calendar months where the day numbers and holidays are too small to read.
This is something I have informally complained about to friends for years, that if you use Google Search for unit conversions, simple arithmetic, and even names of holidays, you get a nice large font “featured snippet” display of exactly your answer. But not something as simple as a month and year or even month with the implication that you want to see the current or next instance of that month.
How hard can that be to build? 12 names of months. 12 more 3-letter abbreviations. Multiplied by however number of languages supported. An intern could code that in under an hour. Someone has likely already written a regular expression for detecting this. (Aside: I tried year first, e.g. 2024 Dec, and hilariously enough that did not work to show the nice month display. So I suspect there is a minimal regular expression under the covers of this Bing feature.)
From having tried search engines for years, I was pretty convinced no one supported this.
Then on a whim I tried this in Bing recently (maybe I hadn’t before?) and to my pleasant surprise it worked.
There you have it, a use-case for Bing that only works in Bing, and reason enough to add a 'b' Search Shortcut in Firefox for Bing.
#search #webSearch #SearchShortcut #Microsoft #BingTip #searchTip #calendar #month
^1 https://tantek.com/2024/287/t2/setup-search-shortcuts-firefox
-
You should setup Search Shortcuts in #Firefox, they have sped up my web browsing experience considerably.
James (@jamesg.blog) wrote up a great summary of how to do so and his experience:
* https://jamesg.blog/2024/10/13/search-engine-shortcuts-firefox/
I use DuckDuckGo as my default search engine, so here are the Search Shortcuts I have setup when I want to explicitly search/lookup something elsewhere, roughly ordered by my perceived frequency of use:
i - IndieWeb - https://indieweb.org/
w - Wikipedia - https://en.wikipedia.org/wiki/
g - Google - https://google.com/
d - MDN Web Docs - https://developer.mozilla.org/
m - Google Maps - https://maps.google.com/
b - Bing - https://bing.com/
a - Amazon - https://amazon.com/
x - Twitter - https://twitter.com/search
If you don’t see one of these search engines in your Firefox Settings: Search Shortcuts, you can visit its URL above and then follow the instructions in James’s blog post to add it to your browser’s list of search engines. Once added there, it will show up in the Search Shortcuts table and you can double-click it and add a one-letter (or more) shortcut as you wish!
What Search Shortcuts have you setup in your browser?
#search #OpenSearch #webSearch #SearchShortcuts #browserTip #FirefoxTip #searchTip
-
No I did not block you on the #fediverse / #Mastodon / #Misskey etc.
If you were following me @tantek.com on your client/server/instance of choice but noticed you were no longer doing so, that was due to a recent software bug in my fediverse provider which accidentally caused everyone’s #ActivityPub servers to unfollow me (bug details below).
No it’s absolutely not your fault, you did nothing wrong.
We need a variant of Hanlon’s Razor^1 like:
“Never attribute to malice that which is adequately explained by a software bug.”
Take another look at my posts if you want (directly on @tantek.com or try searching for that on your instance) and if you like what you see or find them otherwise informative and useful, feel free to refollow. If not, no worries!
Also no worries if you ever unfollow/refollow for any reason. I mean that.
I always assume people know best how to manage their online reader/reading experiences, everyone’s priorities and likes/dislikes change over time, and encourage everyone to make choices that are best for their mental health and overall joy online.
Bug details:
This was due to a #BridgyFed bug^2 that deleted my profile (“ActivityPub actor”) from (nearly?) all instances, making everyone’s accounts automatically unfollow me, as well as remove any of my posts from your likes and reposts (boosts) collections. It also removed my posts from any of your replies to my posts, leaving your replies dangling without reply-contexts. Apologies!
The bug was introduced accidentally as part of another fix about a month ago^3, and was triggered within the following week^4.
Anyone following me before ~2024-09-22 was no longer following me. A few folks have noticed and refollowed. Any likes or reposts of my posts before that date were also undone (removed).
Ryan (@snarfed.org) has been really good about giving folks a heads-up, and apologizing, and quickly doing what he can to fix things.
Bugs happen, yes even in production code, so please do not post/send any hate.
I’d rather be one of the folks helping with improving BridgyFed, and temporary setbacks like this are part of being an early / eager #IndieWeb adopter.
This bug has also revealed some potential weaknesses in other ActivityPub implementations. E.g. deleting an “actor” should be undoable, and undoing a delete should reconnect everything, from follows to likes & reposts collections, to reply-contexts. Perhaps the ActivityPub specification could be updated with such guidance (if it hasn’t been already, I need to double-check).
To be clear, I’m still a big supporter of #BridgyFed, #ActivityPub, #Webmention, and everyone who chooses to implement these and other #IndieWeb related and adjacent protocols as best fits their products and services.
All of these are a part of our broader open #socialWeb, and making all these #openStandards work well together (including handling edge-cases and mistakes!) is essential for providing #socialMedia alternatives that put users first.
References:
^1 https://en.wikipedia.org/wiki/Hanlon%27s_razor
^2 https://github.com/snarfed/bridgy-fed/issues/1379
^3 https://github.com/snarfed/bridgy-fed/commit/4df76d0db7b87cabbd714039546c05b3221169be
^4 https://chat.indieweb.org/dev/2024-09-22#t1727028174623700
This is post 26 of #100PostsOfIndieWeb. #100Posts
← https://tantek.com/2024/285/t1/io-domain-suggested-steps
→ https://tantek.com/2024/306/t1/simple-embeds
-
The SustyWeb IG charter Coordination section says:
“We will also monitor the work of and where appropriate collaborate with standards bodies (external to the W3C) such as those listed below…” and then lists two organizations.
The IETF should be added to this list of standards bodies, perhaps even their
Environmental Impacts of Internet Technology (eimpact) group in particular.
The aspects of coordination could include each group’s email lists, meetings, and perhaps even collaborating on documents.
If it would help, I could start a Pull Request with a basic one-sentence group and coordination description, and invite the editor(s) to make further changes as necessary.
-
I concur with https://github.com/TzviyaSiegman’s comment, and support making “WSG a living document rather than 1.0”.
Sustainability best practices are constantly evolving, related conditions change year over year (such as how power is generated, how devices consume electricity, etc.), and the CG has strong productive momentum which is worth maintaining and focusing on continuously improving the WSG.
The proposed IG charter could be updated accordingly, listing publishing the WSG as an intended living document rather than focusing on a “1.0” deliverable.
-
👍
-
The SustyWeb IG charter Motivation and Background says:
“The Sustainable Web Interest Group will provide evidence-led guidance alongside methods to observe, measure, and improve the sustainability of digital products and services” and then states who will create that guidance.
Before stating who will create the guidance, the charter Background should state who the guidance is intended for. I believe the Web Sustainability Guidelines (WSG) can answer some of this implicitly, however I think it would be helpful for the charter to explicitly state the intended audience. For example (not intended as a specific suggestion), the charter could state something like “This guidance is intended for …” and then perhaps a list of various roles like executives and other decision-makers, managers, designers, developers etc.
I suggest asking the editor(s) of the WSG for a summary of the intended audience, and incorporating that summary into the charter’s Background section. If it would help, I could start a Pull Request with a basic one-sentence suggestion, and invite the editor(s) to make further changes as necessary.
-
⚠️ .io domain^1 likely being phased-out^2 — seven suggested steps
Good article in The Verge summarizing recent .io related events, see that for more context if this is news to you:
* https://www.theverge.com/2024/10/8/24265441/uk-treaty-end-io-domain-chagos-islands
It looks likely .io (and .io domains) will go away in the next few years (as .cs and .yu did^3), so here are my suggested steps to take depending on your usage of .io domains:
1. Avoid buying new .io domains (or making plans with existing ones; sell if you can)
2. If you currently run a .io service^4 (for a company or community), make and publicize a transition plan (like a new domain, redirection, orderly shutdown plan for redirects)
3. If you have a personal site on a .io domain^5 or subdomain, make your own transition plan, and perhaps post about how others should link to your posts
4. If you are using someone else’s .io domain to publish (like #GitHubPages^6), make a transition plan to publish elsewhere and leave a forwarding note and link behind
5. If you use a .io domain as your Web sign-in login on any sites, switch them to another non-io personal domain
6. Similarly if your site accepts #WebSignIn logins (via #IndieAuth, #RelMeAuth, or even #OpenID), consider discouraging any new sign-ups from .io domains, and warning any existing users with .io domains to switch per # 5
7. If you have posts (or a whole #indieweb site) with links to .io sites or pages (like those in 2-4 above), make a plan for editing those links to point to an alternative or an archival copy (like on the Internet Archive)
And of course, post about your #dotIO plans.
Glossary
Domain
https://indieweb.org/domain
IndieAuth
https://indieweb.org/IndieAuth
Internet Archive
https://web.archive.org/
OpenID
https://indieweb.org/OpenID
Redirect
https://indieweb.org/redirect
RelMeAuth
https://indieweb.org/RelMeAuth
Web sign-in
https://indieweb.org/Web_sign-in
References:
^1 https://indieweb.org/.io
^2 https://en.wikipedia.org/wiki/.io#Phasing_Out
^3 https://en.wikipedia.org/wiki/.cs
^4 E.g. https://indieweb.org/webmention.io or https://indieweb.org/granary.io
^5 E.g. https://indieweb.org/werd.io
^6 https://indieweb.org/github.io
This is post 25 of #100PostsOfIndieWeb. #100Posts
← https://tantek.com/2024/283/t1/metaphors-constructive-cooperative-joyful
→ https://tantek.com/2024/287/t1/fediverse-unfollow-bridgyfed-bug
-
I have put a lot of thought into deliberately shifting^1 metaphors^2, often in the context of the #indieweb^3. One goal is to replace use of violent or divisive metaphors with actively constructive, cooperative, or joyful alternatives, like:
* gardening/farming e.g. digital garden^4
* biology/ecology/nature e.g. digital ecosystem^5
* cooking/baking e.g. eat your own cooking^6
* toolmaking, clothing making, other useful crafts e.g. sew what you want^7
* music, dancing, painting, and other expressive crafts e.g. remixing^8
* travel, navigation, maps e.g. information superhighway^9
* games, sports, running, e.g. surfing the net^10
Some of these areas are well developed (sports metaphors), others are obvious or emergent from various IndieWeb efforts like our principles^11, and others could use brainstorming and experimentation.
Thoughts and words, whether spoken or written, influence each other in reinforcement feedback loops. Consciously choosing one can impact the other and vice versa.
Especially in messages to others or our even future selves, words and metaphors communicate and reinforce our values and thus merit care in their invention^12 and usage.
What are metaphors you have found constructive, cooperative, or joyful?
References:
^1 https://tantek.com/2023/132/t1/agenda-gardening-metaphors
^2 https://tantek.com/2023/023/t3/
^3 https://tantek.com/2023/022/t1/indieweb-eat-what-you-cook
^4 https://indieweb.org/digital_garden
^5 https://en.wikipedia.org/wiki/Digital_ecosystem
^6 https://indieweb.org/cook_what_you_want
^7 https://indieweb.org/events/2020-08-19-hwc-west-coast#sewing
^8 https://en.wikipedia.org/wiki/Remix_culture#Analog_era
^9 https://en.wikipedia.org/wiki/Information_superhighway
^10 https://en.wikipedia.org/wiki/Internet_metaphors#Functional_metaphors
^11 https://indieweb.org/principles
^12 https://tantek.com/2024/180/b1/responsible-inventing
This is post 24 of #100PostsOfIndieWeb. #100Posts
← https://tantek.com/2024/277/t2/october-blogtober-indieweb
→ https://tantek.com/2024/285/t1/io-domain-suggested-steps
-
This is primarily a project tracking issue for the Vision Task Force (VisionTF) editor and chair. There are a number of required and a few optional but helpful steps to take before taking the W3C Vision to the Advisory Committee for a vote for a Statement. Notably we need to ensure that proper wide and horizontal reviews have been explicitly requested, and any requests back for more time are properly incorporated.
Here are check-lists of explicit requests for horizontal and wide reviews for customary durations per the W3C Process, with issue links to be added to track each individual request.
Checklist items are initially intended for keeping track of sending requests for reviews, without implying anything about the outcomes thereof. We should also track when we have at a minimum received review feedback from each group that can provide summary feedback from that group.
Before we send these requests for review, we need to publish an updated AB-approved (tracked in the AB’s Member-only repo) public Note based on the current Editor’s draft, for the reviewers to consider:
Horizontal Reviews Requests
Wide Reviews Requests
Wider Outreach
In addition, for such a foundational document, I believe its wide review can benefit from the following optional steps to reach an audience beyond W3C who may have feedback for our consideration:
- [ ] Blog post on W3.org requesting wide review
- [ ] One or more personal blog posts by editor and/or chair
- [ ] Social media copies of or links to said blog posts
Label: Project Vision
-
👍
-
❤️
-
I tend to agree with @github.com/manton’s comment and analysis.
As Manton points out, there are many of us now, many implementers and publishers that are implementing and supporting multiple protocols, and thus it matters to us that we at least maintain the level of compatibility and interoperability that we achieved in the initial Recommendations of these specifications.
I think we can continue to do that, especially if we scope the Working Group to being a maintenance WG for the existing specs. This is something that Evan has convinced me of, while previously I saw a renewed Social Web WG to work on new features. Given the progress with use of extensions, and the Fed ID CG/WG stages process (or something like it), that seems like a better way to pursue new features, in parallel in the Social CG.
Another benefit of one Social Web working group is that its scope is easier to determine and explain, both to prior participants, and to W3C Members who will be voting on its creation.
A renewal of a working group to do maintenance on all of its prior specs, both editorial and bug fixes, makes a lot of sense to W3C and to Members, who like seeing working groups that take up the responsibility of maintaining specs. This especially makes more sense when all those specifications have far more implementations now than when they were shipped by the prior working group!
As I saw in another blog post about the social web, we are all here on “team open”, and I think we suffer, collectively, by attempting to draw lines with any “ActivityPub-only” approach. Both because it unnecessarily divides a very diverse, mixed, and broader “ActivtyPub supporting” community, and because it’s much fuzzier, to the point of overlapping with adjacent and aligned efforts.
The rel=me specification is a good example of this overlap. Would that be included in an “ActivityPub-only” approach? Because it’s certainly used by communities beyond that.
We have a whole task force on HTML Discovery in the CG where some of us (myself included) is working on improving rel=author support when interacting between HTML representations of profiles, yes, often with microformats, and retrieving the JSON(-LD) Activity Streams 2 versions of those profiles. That sort of interoperability benefits from a more inclusive approach.
We have bridges (https://fed.brid.gy/) that have helped the “ActvityPub-verse” grow that we could only dream about during the prior Social Web WG, because that group put in the hard work of figuring out interoperability across protocols and formats. We already did that hard work so why squander it? A maintenance group for all our specs provides a venue for any marginal bits of small work we may (or may not) need to maintain the positive outcomes of all that prior hard work.
Lastly, @github.com/gobengo brings up important concerns that I think merit explicitly addressing, regarding “experience in the SocialWG from 2013-2017” (actually 2014-2018 per https://www.w3.org/wiki/Socialwg)
First, in summary I will say as the saying goes “Don't fight the last war”, or I prefer a non-violent expression instead: “Don’t argue the prior debates”.
We were in a very different situation at the start of the first Social Web Working Group, having emerged from an incredibly diverse “W3C Workshop on Social Standards: The Future of Business” (AKA osfw3c) in 2013.
The first Social Web WG had to evaluate numerous prior group efforts (17+) and different approaches (~15) that were proposed by members of the group for consideration before narrowing down to ~3 approaches. Lots of time was spent doing this, which we would obviously avoid by sticking to maintenance of existing specs.
We also found so much in common that we were able to leverage as building blocks and points of compatibility. HTTP & link rel discovery. URLs for profiles. Etc. the list goes on.
All of that is pointing out how the first Social Web WG was very different than what a similarly scoped Social Web WG could be like today.
Second, the other strong point of more recent evidence that we should use instead of fearing “the last war”, is how the Social CG has been conducted for the past 5-6 years, especially the past few years mostly chaired by Dmitri.
Every Social CG meeting I have been to has been incredibly positive & productive. Even when we disagree, we do so in very civil, polite, informed ways that consider each other’s use-cases, perspectives, opinions, with folks working on different projects and protocols! It has been an incredible experience and I am grateful to be a part of it, and especially grateful for Dmitri’s stewardship. I mentioned this briefly in a post after a recent meeting https://tantek.com/2024/216/t1/socialcg-telcon.
With the Social CG, under Dmitri’s chairing, we have found a new more harmonious rhythm, and frankly, broader inclusiveness of different efforts and communities than we ever had previously. We have proven we can have regular meetings that “continue[s] the work of the W3C Social Web Working Group” where agenda items are curated and prioritized in a manner that respects the time and interests of the participants.
I would expect the harmony of the Social Web CG to continue in a similar renewed Social Web WG, and would support Dmitri as a co-chair of that working group to keep our momentum going. In addition, I would ask anyone else wanting to co-chair to learn from and adopt Dmitri’s chairing workmode accordingly. I believe that is our best path to success for this community, and for all our collective goals.
References:
* https://www.w3.org/wiki/SocialCG
* https://www.w3.org/wiki/SocialWG
* https://indieweb.org/2013/osfw3c
-
👍
-
Happy October!
For some reason this month has a plethora of daily blogging or other creativity prompts. Here’s a list of the ones I found so far:
* #Blogtober (consider this post my first for this, retroactively day 1)
* Inktober — https://inktober.com/
* LOLtober - https://weblog.anniegreens.lol/2024/10/loltober-2024
* Looptober — https://looptober.com/
* Mathober - https://mathober.com/
* Viztober — https://www.instagram.com/evalottchen/p/DAiNm3ZtuTj/
Having found so many for the month I created an “October” page on the #IndieWeb wiki to document them all (and in case folks find others to add):
* https://indieweb.org/October
October is also a very popular month for seasonal blog styling:
* https://indieweb.org/Halloween
Do you have a custom Halloween theme for your personal site? Add it to the wiki!
This is post 23 of #100PostsOfIndieWeb. #100Posts
← https://tantek.com/2024/247/t4/w3c-link-checker-before-federating
→ https://tantek.com/2024/283/t1/shifting-metaphors-constructive-cooperative
-
Last week I participated in #w3cTPAC 2024^1 in Anaheim, California. It was quite packed, and often started early, from 8am informal breakfast meetings at a nearby IHOP, to Working Group, Community Group, and other small group meetings every day (but Wednesday) til 18:00.
Midweek at TPAC was the usual Breakouts Day where a record 87 breakouts^2 were proposed^3 and run by members of the community, deftly organized into rooms, timeslots, and a handful of themes^4 by the W3C Team. In the evening there was an open Plenary Session^5 open to all instead of an Advisory Committee (AC) meeting, where the result of the recent W3C Board Election^6 was announced. Congratulations to the newly elected W3C Board of Directors!
I’m still compiling my own notes and observations. For now, the minutes of (nearly?) all the meetings and breakouts are available if you know how to find them.
Hint: W3C minutes URLs have the form (without spaces):
https:// www . w3 . org / YYYY / MM / DD-IRCNAME-minutes . html
E.g. to find the second day (2024-09-24) of CSS Working Group (which just uses "css", all lower case, as their IRC channel name) minutes, you would go to:
* https://www.w3.org/2024/09/24-css-minutes.html
Every Working Group and Community Group links to its IRC Channel (all lowercase), and breakout proposals link to the channel used for each breakout. Thus the minutes links to specific groups on specific days are left as a web discovery exercise for the reader.
Last year: https://tantek.com/2023/262/b1/w3c-technical-plenary-tpac
^1 https://www.w3.org/wiki/TPAC/2024
^2 https://www.w3.org/2024/09/TPAC/breakouts.html#grid
^3 https://github.com/w3c/tpac2024-breakouts/
^4 https://github.com/orgs/w3c/projects/57/views/1
^5 https://www.w3.org/2024/09/26-tpac-minutes.html
^6 https://www.w3.org/2024/09/26-tpac-minutes.html#x215
-
❤️
-
👍
-
> Should we just close this issue then?
No, because this issue as named is to “integrate” which is still a pending task separate from the Team task of “updated proposal”.
> just a reminder to the Team to keep things in sync as needed
No, that is missing half the point of this issue. By “in both directions” (per issue description) I believe it means that the chair/editor of the Vision have explicit work to do in the direction of incorporating content into the Vision document.
I disagree with “Candidate to Close” and do not think it needs AB time to discuss closing at this time, thus am removing that label.
If you believe this issue needs explicit sync-discussion by the AB at this time, please add “Agenda+” instead with your goals for discussion.
-
👍
-
👍
-
👍
-
👍
-
Quoting from
this comment on issue 113
to separate this into its own issue:
…we need to do an adversarial reading of the document, to anticipate how it will be understood and misunderstood by people outside the consortium -- especially those who may not be predisposed to be 'on board' with what we do.
This will likely require a section by section reading, and filing new specific issues per potential misunderstanding to consider how and if there is way to mitigate such potential misunderstandings. Such new issues should cite this issue and then we can make closing this issue dependent on closing all such specific issues.
We may want to consider a list of checkboxes in this issue to track completion of such adversarial reading analyses section by section.
-
👍
-
Closing with editorial change (https://github.com/w3c/AB-public/pull/175) merged to include "and the Vision Task Force" per Vision Task Force resolution: https://www.w3.org/2024/09/25-vision-minutes.html#r03
-
Removing "needed for Statement" label but leave issue open for further iterative improvements per Vision Task Force resolution:
https://www.w3.org/2024/09/25-vision-minutes.html#r04
-
It has been a while since the most recent discussions on this issue.
Since then, I will note that I have heard anecdotal experience from the Team and others regarding using the W3C Vision Note in their decision-making and they have found it quite useful, in everything from chartering, to resolving objections (often amciably), to recruiting.
Thus I propose that we close this issue as complete or complete enough to proceed to Statement.
If we get new information or new experiences (where people tried to use the Vision to make hard decisions and found it lacking), then we should open new issue(s) for those specific opportunities for improvement.
-
The editor and chair of the Vision Task Force met with W3C team members working on a proposed update to the W3C mission statement and we (VisionTF) are currently waiting on an updated proposal for presentation to the Task Force. We hope to see this proposed update sometime this month or next month.
-
@github.com/plehegar regarding: “Will the Social Web charter part of the scope of this breakout?”
I support discussing next steps on a Social Web WG charter in this breakout, in particular, using the discussion and links in https://github.com/w3c/strategy/issues/435 to help us make forward progress.
-
@github.com/plehegar regarding:
> Can we turn the proposal (https://www.w3.org/wiki/SocialCG/WG_Charter_Discussion) into a charter?
I think that proposal made good progress on some sections of a potential future Social Web WG charter as of meetings and discussions 6-12 months ago.
However, given the CG/WG Proposal Stages you linked us to above, I think it would be worth splitting the large table of Deliverables into two tables for consideration:
* Specs published by the prior Social Web WG — for necessary maintenance
* New proposals or draft specs - for working through stages
Without objection, I can do the wiki-table editing to split up that draft table of deliverables so it matches better with the CG/WG Proposal Stages proposal.
(Please thumbs-up as encouragement if you support this)
-
@github.com/plehegar I read that FedID CG/WG Proposal Stages proposal (https://github.com/w3c-fedid/Administration/blob/main/proposals-CG-WG.md) and it makes a lot of sense to me as a thoughtful and rational methodology to incubate ideas and proposals in a CG through levels and when to uplift a proposal into the corresponding WG. I support it.
I think this would work well for numerous technical proposals being discussed in the Social Web CG to help them evolve and advance iteratively, and provide a more explicit way to evaluate them (independent of their specific topic or technology) for taking up by a potential future Social Web WG.
-
👍
-
👍
-
👍
-
👍
-
👍
-
👍
-
Dear Creative Commons (@creativecommons.org @creativecommons@mastodon.social @creativecommons@x.com),
Can we have CC-NT licenses for no-training (ML/LLM, GenAI in general), just like we have CC-NC for non-commercial?
My previous post^1 reminded me that I’ve been creating, writing, inventing, and then sharing things with #CreativeCommons (CC) #licenses for a long time (I have to see if I can dig up my first use of CC licenses.)
I’ve used and recommended a variety of CC licenses for decades, e.g.
* CC0 — for standards work, e.g. I drove and wrote up https://wiki.mozilla.org/Standards/licensing (with help from lawyers)
* CC-BY — aforementioned blog post (and other snippets of #openSource)
* CC-BY-NC — photos on Flickr (dozens of which have been used in publications^2)
* CC-SA — for CASSIS^3, which I still consider experimental enough that I chose "share-alike" to deliberately slow its spread, and hopefully reduce mutations (while allowing ports of its functions to other languages)
So I have some idea of what I’m talking about.
There have been LOTS of discussions of the challenges, downsides, and disagreements with sweeping use of copyrighted content to train generated artificial intelligence AKA #genAI software and services, sometimes also called #machineLearning. The most common examples being Large Language Models AKA #LLM, but also models for generating images and video. Smart, intelligent, and well-intentioned people disagree on who has rights to do what, or even who should do what in this regard.
There have been many proposals for new standards, or updates to existing standards like robots.txt etc. but I have not really seen them make noticeable progress. There are also lots of techniques published that attempt to block the spiders and bots being used to crawl and collect content for GenAI, an arms race that ends up damaging well-established popular uses such as web search engines (or making it harder to build a new one).
The brilliant innovation of Creative Commons was to look at the use-cases and intentions of creators publishing on the web in the 2000s and capture them in a small handful of clear licenses with human readable summaries.
Creatives are clamoring for a simple way to opt-out of their publicly published content from being used to train GenAI. New Creative Commons licenses solve this.
This seems like an obvious thing to me. If you can write a license that forbids “commercial use”, then you should be able to write a license that forbids use in “training models”, which respectful / well-written crawlers should (hopefully) respect, in as much as they respect existing CC licenses.
I saw that Creative Commons published a position paper^4 for for an IETF workshop on this topic, and it unfortunately in my opinion has an overly cautious and pessimistic (outright conservative one could say) outlook, one that frankly I believe the founders of Creative Commons (who dared to boldly create something new) would probably be disappointed in.
First, there is no Creative Commons license on the Creative Commons position paper. Why?
Second, there are no names of authors on the Creative Commons position paper. Why?
Lots of people similarly (to the position paper) said the original Creative Commons licenses were a bad idea, or would not be used, or would be ignored, or would otherwise not work as intended. They were wrong.
If I were a lawyer I would fork those existing licenses and produce such “CC-NT” (for “no-training”) variants (though likely prefix them with something else since "CC" means Creative Commons) just to show it could be done, a proof of concept as it were that creators could use.
Or perhaps a few of us could collect funds to pay an intellectual property lawyer to do so, and of course donate all the work produced to the commons, so that Creative Commons (or someone else) could take it, re-use it, build upon it.
Someone needs to take such a bold step, just as Creative Commons itself took a bold step when they dared to create portable re-usable content licenses that any creator could use (a huge innovation at the time, for content, inspired in no doubt by portable re-usable open source licenses^5).
References:
^1 https://tantek.com/2024/263/t1/20-years-undohtml-css-resets
^2 https://flickr.com/search/?user_id=tantek&tags=press&view_all=1
^3 https://tantek.com/github/cassis
^4 Creative Commons Position Paper on Preference Signals, https://www.ietf.org/slides/slides-aicontrolws-creative-commons-position-paper-on-preference-signals-00.pdf
^5 https://en.wikipedia.org/wiki/Comparison_of_free_and_open-source_software_licenses
-
20 years and two weeks ago, I came up with undohtml.css and unknowingly invented the mechanism of CSS Resets (AKA reboot or reset style sheets^1) which spawned numerous variants, many still in broad use on the web today.
https://tantek.com/log/2004/09.html#d06t2354
A one sentence problem description, and a short paragraph describing my problem-solving, actions, license, link to less than 300 bytes of code (not counting comments), and a few future thoughts.
The rest of that blog post was about “debug scaffolding”, the part I thought was more interesting at the time.
Eric Meyer (@meyerweb.com @meyerweb@mastodon.social) followed up ~10 days afterwards with his thinking and improvements:
* https://meyerweb.com/eric/thoughts/2004/09/15/emreallyem-undoing-htmlcss/
where he mentioned “resetting” in passing, but not actually calling it a "reset".
~2.5 years later Eric published “Reset Styles” with further reasoning and improvements:
* http://meyerweb.com/eric/thoughts/2007/04/12/reset-styles/
describing them as: “reset” or “baseline” set of styles.
Subsequently he iterated in several more blog posts:
* http://meyerweb.com/eric/thoughts/2007/04/14/reworked-reset/
* http://meyerweb.com/eric/thoughts/2007/04/18/reset-reasoning/ — this is Eric’s first post where he explicitly calls them “reset styles”, which I believe is the origin of the eventual phrase “CSS Reset” and “reset style sheets”
* http://meyerweb.com/eric/thoughts/2007/05/01/reset-reloaded/ (yes a Matrix: Reloaded reference)
~6 months later Eric published his evergreen resource “CSS Tools: Reset CSS”
* https://meyerweb.com/eric/tools/css/reset/
which, as you see within the URL: “css/reset”, is perhaps where the phrase “CSS Reset” comes from, and it’s also the label (link text) he gives that page in his UI about-page^2 and the first content link in his 404 page^3.
My technology invention takeaways from all this:
1. if you find yourself repeatedly solving the same (especially annoying) problem, create a re-usable solution that works for you
2. write up your problem statement / use-case in only one sentence
3. publish your solution (on your personal site^4), name it something short, with only a short paragraph description, and re-use/remix friendly license (like Creative Commons)
And things not to worry about (that may get in your way to publishing):
1. perfecting or making your solution “big enough” or “the right size”. does it solve your problem? then it’s already the right size.
2. coming up with the perfect name. instead, name it what it does. someone might come up with a better name weeks, months, or years later. let them run with it!
3. waiting to blog multiple things. I could have blogged undohtml.css by itself, probably should have, and instead lumped it into a blog post with another CSS thing I came up with.
Further reading and resources for CSS Resets:
* More history: https://css-tricks.com/reboot-resets-reasoning/
* Large collection: https://perishablepress.com/a-killer-collection-of-global-css-reset-styles/
References:
^1 https://en.wikipedia.org/wiki/Reset_style_sheet
^2 https://meyerweb.com/ui/about.html
^3 https://meyerweb.com/404
^4 https://indieweb.org/
#undoHTML #undoHTMLCSS #reset #CSSreset #resetstyles #webdesign #technology #invention #indieweb
-
Session description
The Sustainability Community Group (CG) identified a number of
projects and work areas in its first meeting.
Since then, two things key things have happened:
First, the Sustainable Web Design CG has been forked off to its own
in-progress Interest Group charter
(on w3c-ac-members member only link) to focus on the Web Sustainability Guidelines. Thus this Sustainability meeting will focus on other areas listed.
Second, the Ethical Web Principles (EWP) has been voted on by the W3C Advisory Committee, and there were no objections to the section on environmental sustainability, which provides an excellent forward-looking focus for a Sustainability CG meeting.
Session goal
The goal of this session is to discuss and pick a few of the Sustainability CG work areas that are most directly and actionably aligned with the EWP encouragement to “endeavor not to do further harm to the environment when we introduce new technologies to the web”, and identify goals and next steps towards those goals. For example, expanding on the Principles identified by the EWP, and how to do a sustainability (s12y) assessment of new and proposed technologies towards establishing a practice of Sustainability Horizontal Reviews to build on W3C’s existing accessibility (a11y), internationalization (i18n), security, and privacy horizontal reviews.
Additional session chairs (Optional)
No response
Who can attend
Restricted to TPAC registrants
IRC channel (Optional)
#sustainability
Other sessions where we should avoid scheduling conflicts (Optional)
#55,
#59,
#65,
#68,
#70,
#77,
#84,
#87,
#88,
#89,
#99
Instructions for meeting planners (Optional)
No response
Agenda for the meeting.
To be added to https://www.w3.org/wiki/Sustainability if this session is approved.
-
Session Description
The Advisory Board (AB) published the
W3C Vision as a Note
earlier this year. The Vision Task Force
(VisionTF)
has processed most issues and a small number of Statement Blockers remain. This breakout session is an open session for working through the remaining
Statement Blocker issues.
Session goal
The goal of this session is reach consensus resolutions on the remaining Statement Blocker issues for the W3C Vision, so the Vision Task Force can prepare an updated W3C Vision Note for publication as a proposed Statement for an Advisory Committee vote.
Additional session chairs (Optional)
@cwilso
Who can attend
Restricted to TPAC registrants
IRC Channel (Optional)
#vision
Other sessions where we should avoid scheduling conflicts (Optional)
#55,
#59,
#65,
#68,
#70,
#77,
#87,
#88,
#89,
#99,
#100
Instructions for meeting planners (Optional)
No response
Agenda for the meeting.
w3.org/wiki/AB/VisionTF/2024-09-25
-
Happy #8bitday — 256th day of the year! Here’s some reasons to celebrate:
bit = portmanteau of binary digit
8 binary digits can represent 256 different numerical values
8 bits are also a byte, the fundamental unit of computer storage — 'B' is for byte in 'GB' or 'TB' as an amount of memory (e.g. 24GB) or disk space (e.g. 2TB).
The '8' in UTF-8 also stands for 8 bits.
Beyond computer connections, there’s lots of 8-bit music and other forms of art.
Previously, previously, previously:
* https://tantek.com/2015/256/t2/happy-8bitday-this-year-konamicode
* https://tantek.com/2014/256/b1/happy-8-bit-day-8bitday
* https://tantek.com/2013/256/t1/happy-8-bit-day
* https://tantek.com/2012/256/t2/portland-xoxo-happy-8bitday
* https://tantek.com/2010/256/b1/happy-8-bit-day
* https://twitter.com/t/status/3960099908
Glossary
8-bit music
https://tantek.com/w/8bitday#Music
bit
https://en.wikipedia.org/wiki/Bit
byte
https://en.wikipedia.org/wiki/Byte
Gigabyte (GB)
https://en.wikipedia.org/wiki/Gigabyte
UTF-8
https://en.wikipedia.org/wiki/UTF-8
-
likes thisismissem’s toot
-
Came up with and tried a three phase pomodoro technique yesterday for working thru tasks and projects.
This three phase pomodoro cycle repeats and resyncs hourly. The three phases I came up with:
* physical tidying/cleaning
* physical processing
* digital processing
This worked quite well and I got a lot of things done, tasks completed or significantly advanced in ~6 hours.
Many of these were “annoying” or “boring” but often not immediately “necessary” tasks that I had left undone (procrastinated) for many weeks, especially with all the travel I have had in the past two months nevermind first two-thirds of this year.
I took the basic idea of a pomodoro 20-minute timebox^1, figured three of those fit into an hour, and picked three things that were cognitively different enough that switching from one to the other would use different cognitive skills (perhaps different parts of my brain), thus allowing a form of cognitive rest (rather than fatigue, and giving one part of my brain a chance to rest, while using others).
This eliminated the need to take “pomodoro breaks”, whether 5 minutes or 20-30 minutes and it felt nearly effortless (actually fun at times) to cycle through the three phases, repeatedly, for hours on end. Before I knew it six hours had gone by and many tasks had been completed.
The three 20 minute phases have the advantage of quickly determining at any time which phase you should be in by checking your watch/phone for :00-:20, :20-:40, :40-:00. If you happened to be “out of phase”, e.g. “run over” because you were finishing something up, rather than stressing about it, switch to the in-progress phase and pick-up a new task accordingly.
A 20 minute timebox also has the advantage that tasks are less annoying or boring when you know that in less than 20 minutes you will be able to set them down and switch to something else.
There was an iterative sense of expectation of novelty. The expectation of even only a little novelty was enough to make things go more quickly in the present, and even provide a game-like encouragement of see how far I can get with this boring or annoying task in the little time remaining. Could I even complete this one task in less than 20 minutes?
I think repeating three phase pomodoro cycles worked particularly well on a Saturday afternoon when I had very few external interrupts. I think that was key. It gave a sense of momentum, if actual flow^2, that itself felt like it gave me a source of energy to keep going. I’m not sure it would work during normal work hours in any highly or even partially collaborative environment.
Interruptions for physical needs, moving around, drinking, eating etc. were something that I allowed at any time, and that removed any stress about those too.
I rarely set any count-down timers. A few times when I recognized I was starting or picking up a task that I might get absolutely lost in (such as many digital processing tasks like email), I set an explicit count-down timer for the end of the phase. These timer alarms certainly helped to give me permission to put down that task (for now) and switch, rather than feeling compelled to “complete” it which I know from experience can often take much longer, and leave me feeling more tired, perhaps even too tired to do anything else.
There was also a sense of relief in knowing that even if I didn’t finish a particular task by the end of a phase, I would have the opportunity to pick it right back up in 40 minutes. Or maybe by then I would have decided to work on a different task in that phase.
This three phase pomodoro technique worked well for tasks that are not very cognitively engaging (hence boring or annoying). Such tasks have low context, and thus low context-switching costs, but still benefit from taking mental breaks and resets.
In contrast, any deeply cognitively engaging, thinking, or creative tasks, like inventing, coding, writing, typically have a much higher context-switching costs, and in my experience work better when you can set aside a longer block of time to allow yourself build up all the context and then joyfully explore the depths of whatever it is you’re creating.
That being said, I think some creative tasks (depending on the person) could benefit from time-boxing. Like having a constraint to write a short blog post in the morning before a workout or breakfast. Worth trying such one-off timeboxes or even formal pomodoros and seeing if they help complete some creative tasks faster (or more often) over time.
#productivity #pomodoro #pomodoroTechnique #gtd #gettingThingsDone #Saturday
References:
^1 Apparently I misremembered 20 minutes instead of the typical pomodoro 25 minutes: https://en.wikipedia.org/wiki/Pomodoro_Technique
^2 https://en.wikipedia.org/wiki/Flow_(psychology)
-
Tip: use the W3C Link Checker and fix any errors before federating with Bridgy Fed.
https://validator.w3.org/checklink
If you are using Bridgy Fed to federate your posts from your personal site, I highly recommend you first run the W3C Link Checker on a post, and verify there are no “red” errors (or fix any you find), before pinging Bridgy Fed to federate the post.
The reason is that if your post contains broken links, especially broken https: links as part of an @-mention, a weird set of timeout interactions will occur between #BridgyFed and #Mastodon that will cause any Mastodon instances following your posts to drop your federated posts as if they had not been received.
Further, those instances will also ignore any UPDATES to that post.
More discussion here:
* https://chat.indieweb.org/dev/2024-09-04#t1725421768496000
More bug details here:
* https://github.com/snarfed/bridgy-fed/issues/884#issuecomment-2327861883
#IndieWeb #federate #fediverse #interoperability
This is post 22 of #100PostsOfIndieWeb. #100Posts
← https://tantek.com/2024/246/t1/adventures-indieweb-activitypub-bridgy-fed
→ https://tantek.com/2024/277/t2/october-blogtober-indieweb
-
@thisismissem@hachyderm.io we’ve tracked the bug down to one or more problems stemming from having a link in a post to an https: URL that fails to resolve or times out, in the context of an @-mention.
Bridgy Fed is attempting to fetch it and times out. When a #fediverse instance fetches the AS2 version of a post, and Bridgy Fed attempts to fetch that post’s links to construct the AS2 for the post, Bridgy Fed times out, which then likely times out the original AS2 request, so #Mastodon instances never get the requested AS2 post.
There are multiple possible problems:
* content authoring errors (including bad links, links going bad)
* Bridgy Fed attempting to retrieve every link in a post in order to construct the AS2 for a post, possibly with too long timeouts, so the overall AS2 construction takes too long
* Mastodon timing out when requesting the AS2 for a post, then giving up and never trying again (e.g. even when it receives an UPDATE for the post)
More discussion here:
* https://chat.indieweb.org/dev/2024-09-04#t1725421768496000
More details here:
* https://github.com/snarfed/bridgy-fed/issues/884#issuecomment-2327861883
#BridgyFed #atMention #ActivityStreams2
-
Twenty years ago this past February, Kevin Marks and I introduced #microformats in a conference presentation.
Full post: https://tantek.com/2024/044/t1/twenty-years-microformats
Aside: This is an even shorter summary of that post from ~200 days ago, which #Mastodon readers never got due to a Mastodon #federation bug (details in https://tantek.com/t5Yo1).
Since early 2023, here are the top three updates & interesting developments in microformats:
1. Growing rel=me adoption for distributed verification (✅ in Mastodon etc.)
* Wikipedia, Threads, omg.lol
2. Proposal to merge #microformats2 h-review into h-entry, since in practice (e.g. on #indieweb) reviews are just entries with a bit more.
3. #metaformats adoptions, implementations, iteration
-
Twenty years ago this past February, @KevinMarks.com (@KevinMarks@xoxo.zone) and I introduced #microformats in a conference presentation.
Full post: https://tantek.com/2024/044/t1/twenty-years-microformats
Aside: This is a summary of a longer post from ~200 days ago^1, which #Mastodon readers never got due to a Mastodon #federation bug (instances returned 202 for post inbox delivery, but did not show post to followers or on local profiles, details in https://tantek.com/t5Yo1).
I wrote a retrospective last year: https://tantek.com/2023/047/t1/nineteen-years-microformats
Since then, here are the top three updates & interesting developments in microformats:
1. Growing rel=me adoption for distributed verification (✅ in Mastodon etc.)
* Wikipedia, Threads, omg.lol support
2. A proposal to merge #microformats2 h-review into h-entry, since reviews are in practice (e.g. on the #indieweb) always entries with a bit more information.
3. #metaformats adoptions, implementations, and iteration
More details:
^1 https://tantek.com/2024/044/t1/twenty-years-microformats
-
Adventures in IndieWeb / ActivityPub (AP) bridging:
While in general my posts are being successfully federated by https://fed.brid.gy/ #BridgyFed, most of my recent posts, and two more earlier this year, were delivered successfully to multiple #Mastodon instances AP inboxes (returned 202), however the posts do not show up if you look-up my profile on those instances (and thus followers never saw them).
Update: workaround found: https://tantek.com/2024/247/t4/w3c-link-checker-before-federating
These very recent posts:
* https://tantek.com/2024/247/t2/twenty-years-microformats-shorter
* https://tantek.com/2024/247/t1/twenty-years-microformats-summary
* https://tantek.com/2024/245/t1/read-write-suggest-edit-web
* https://tantek.com/2024/242/t1/indiewebcamp-portland
* https://tantek.com/2024/238/t3/indiewebcamp-auto-linking
and these earlier this year:
* https://tantek.com/2024/173/t1/years-posse-microformats-adoption
* https://tantek.com/2024/044/t1/twenty-years-microformats
were all delivered to over 300 instances, which returned "202" codes, however none of them show up in profile views on those instances, e.g.
* https://indieweb.social/@tantek.com@tantek.com
* https://mastodon.social/@tantek.com@tantek.com
* https://social.coop/@tantek.com@tantek.com
* https://w3c.social/@tantek.com@tantek.com
(My most recent post on all of these is the same 2024-08-25 post starting with “All setup here at IndieWebCamp Portland!”)
Why would a Mastodon instance respond with a 202 to an AP inbox delivery and then not show that post on the local profile view?
GitHub tracking bug in case you can help narrow/track this down or have
* https://github.com/snarfed/bridgy-fed/issues/884
Let’s see if this post makes it to your Mastodon (or other #fediverse) reader/client.
Update: ironically this very post itself (with plenty of links, including links to my domain) showed up so I’m quite confused why Mastodon is dropping some posts and not others.
Update 2: it appears all the posts that Mastodon dropped on the floor have @-domain references, e.g. to @-KevinMarks-.-com (without the "-"s). When I changed that @-domain mention to just “Kevin Marks” in https://tantek.com/2024/247/t2/twenty-years-microformats-shorter, it got delivered and shown on Mastodon no problem, with a new slug of https://tantek.com/2024/247/t2/twenty-years-microformats-shorter2.
Something about the ActivityStreams2 that BridgyFed is generating for hyperlinked @-domain mentions is causing Mastodon to choke and fail to show the post to followers and in a local profile.
#indieweb #ActivityPub
This is post 21 of #100PostsOfIndieWeb. #100Posts
← https://tantek.com/2024/245/t1/read-write-suggest-edit-web
→ https://tantek.com/2024/247/t4/w3c-link-checker-before-federating
-
✏️ I want the Read Write Suggest-Edit Accept-Edit Update Web.
The consumer Infinite Scroll Web leaves us feeling empty.
Too few of us participate in the Read Write Web, whether with personal sites or Wikipedia.
A week ago when we wrapped up #IndieWebCamp Portland and I was reading Kevin Marks (@kevinmarks@indieweb.social) live-tooting of the demos^1, I noticed a few errors, typos or miscaptures, and pointed them out in-person.
Kevin was able to quickly edit his toots and update them for anyone reading, thanks to #Mastodon’s post editing feature and its support of #ActivityPub Updates. But this shouldn’t require being in the same room, whether IRL or chat.
We should be able to suggest edits to each other’s posts, as easily as we can reply and add a comment.
13 years ago I wrote^2:
“The Read Write Web is no longer sufficient. I want the Read Fork Write Merge Web.”
Now I want the Read Write Suggest-Edit Accept-Edit Update Web.
The ↪ Reply button is fairly ubiquitous in modern post user interfaces (UIs).
Why not also a ✏️ Suggest Edit button, to craft a fix for a typo, grammar, or other minor error, and send the author for their review, and acceptance or rejection? Perhaps viewable only by the suggester and the author, to avoid "performative" suggested edits.
If the author’s posts provide revision histories, when a suggested edit is accepted, a post’s history could show the contributor of the edit.
Instead of asking Kevin in-person, what if I could have posted special "Suggested Edit" responses in reply to his toots, for which he would receive special notifications, and could choose to one-click accept and update (or further edit) his toots?
To enable such UIs and interactions across servers and implementations, we may need a new type of response^3, perhaps with a special property (or more) to convey the edits being suggested.
There is documentation of this and similar use-cases, prior art / UIs, as well as some brainstorming on the #IndieWeb wiki:
* https://indieweb.org/edit
Our interaction after IndieWebCamp has inspired me to take another look at how can we design and prototype solutions to this problem.
For now, if you host your blog and posts as static files on GitHub (or equivalent), you could add a button like this to your posts alongside Like, Reply, Repost buttons:
✏️ Suggest Edit
and link it to an edit URL for the static file for the post.
I don’t use GitHub static files myself for posts, but here’s an example of such an edit link for one of my projects:
https://tantek.com/github/cassis/edit/main/README.md
This will start the process of creating a “pull request”, GitHub’s jargon^4 for a “suggested edit”.
After completing GitHub’s ceremony of entering multiple text fields (summary & description), and multiple clicks to create said “pull request”, it’ll be sent to the author to review. Presuming the author likes the suggested edit, they can perform the other half of GitHub’s jargon-filled ceremonies to “Merge” or “Squash & Merge”, “Delete fork”, etc. to accept the edit.
It’s an awkward interaction^5, however useful for at least prototyping a ✏️ Suggest Edit button on sites that store their posts as files in GitHub. Certainly worthy of experimenting with and gathering experience to design and build even better interactions.
We can start with the shortest path to getting something working, then learn, iterate, improve, repeat.
#readWriteWeb #editableWeb #suggestEdit #acceptEdit
References:
^1 https://indieweb.social/@kevinmarks/113025295600067213
^2 https://tantek.com/2011/174/t1/read-fork-write-merge-web-osb11
^3 https://indieweb.org/responses
^4 The phrase “pull request” was derived from the git command: “git request-pull” according to https://www.reddit.com/r/git/comments/nvahcp/comment/h12hzj7/
^5 “edits” in GitHub require taking far more steps, and navigating far more jargon, then say, Wikipedia pages, which come down to “Edit” and “Save”. We should aspire to Wikipedia’s simplicity, not GitHub’s ceremonies.
This is post 20 of #100PostsOfIndieWeb. #100Posts
← https://tantek.com/2024/242/t1/indiewebcamp-portland
→ https://tantek.com/2024/246/t1/adventures-indieweb-activitypub-bridgy-fed
 t
t